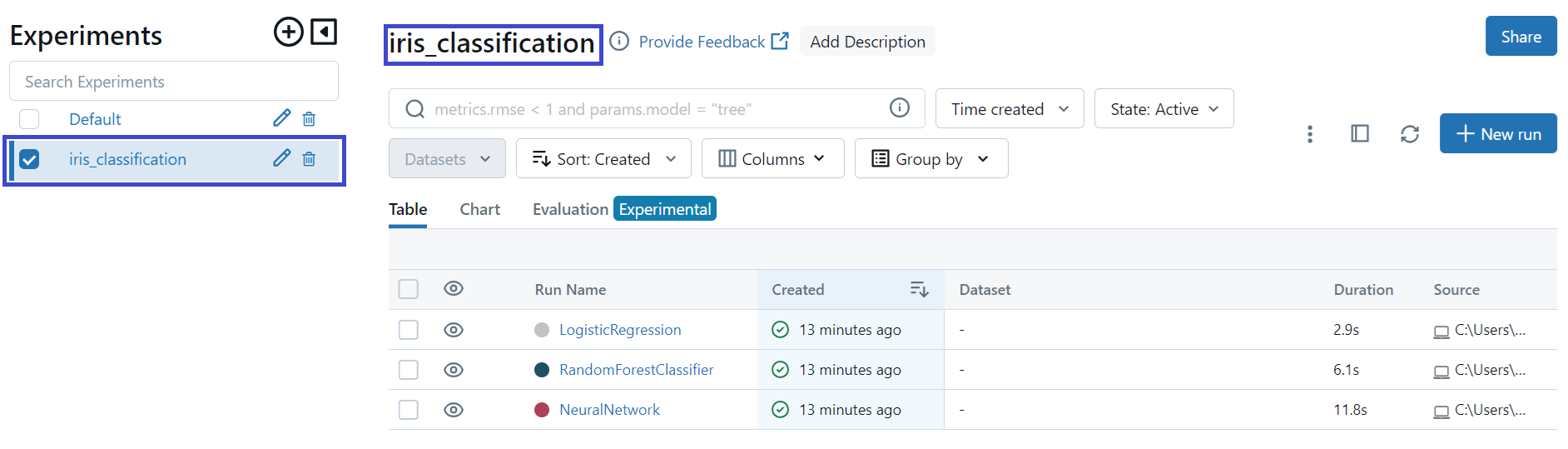
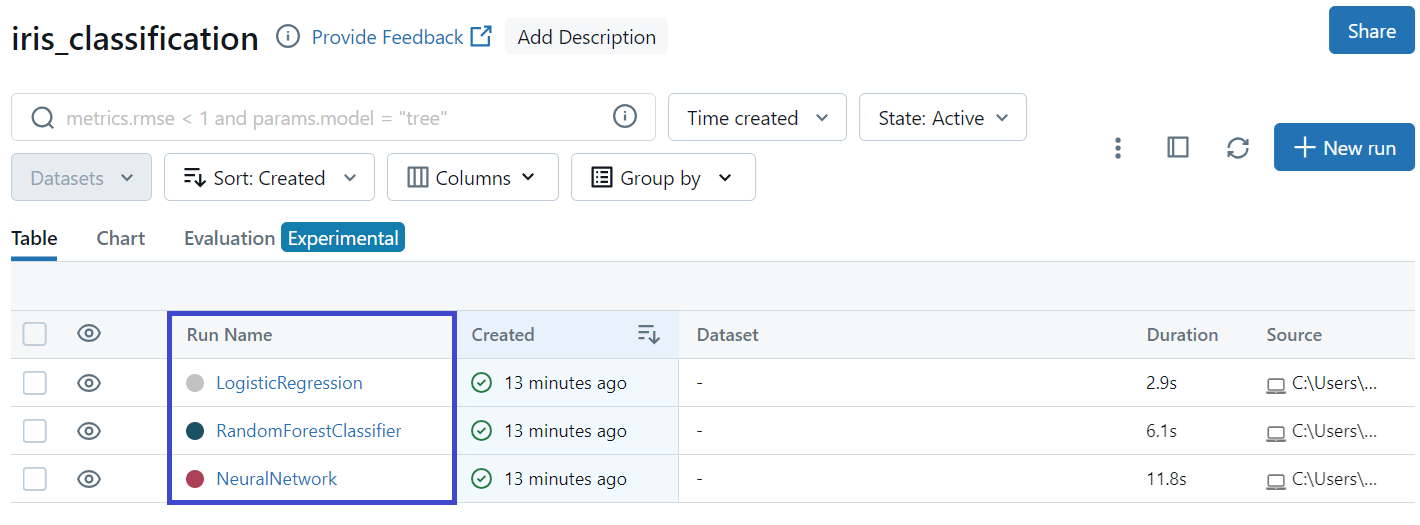
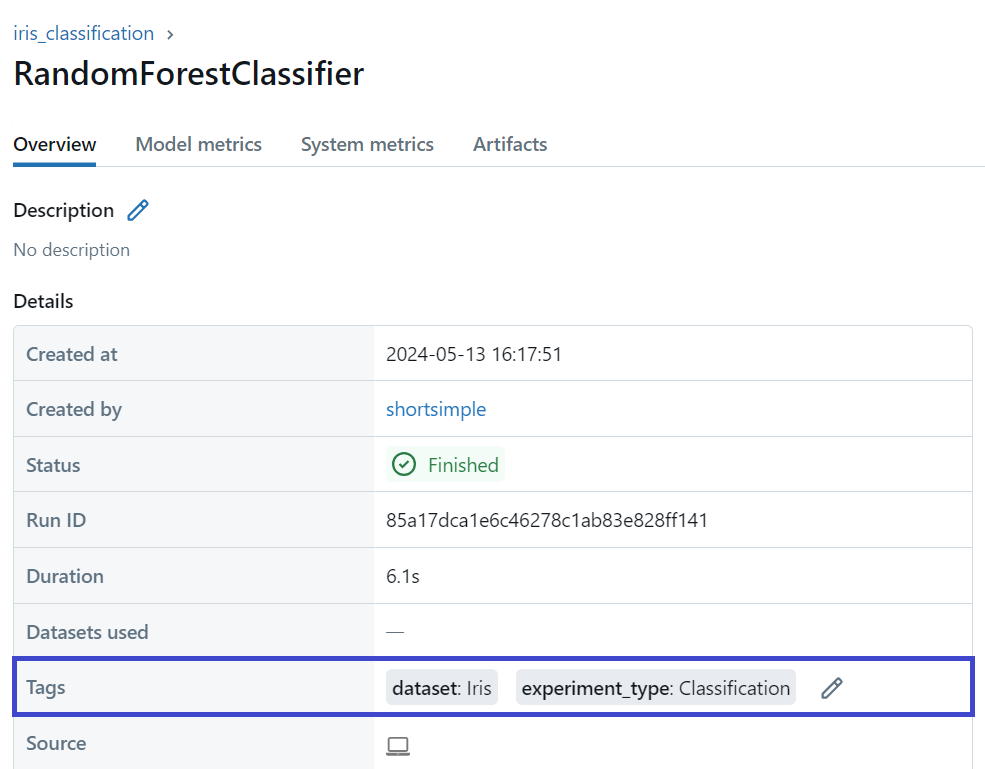
Scikit-learn의 Iris 데이터셋에 대해 실습을 해보았다.
https://github.com/yehoon17/mlflow-tutorial
1. MLflow 설정 및 실행
MLflow 트래킹 URI 설정
.env 파일 생성
1
| MLFLOW_TRACKING_URI=file:///path/to/your/root/mlruns
|
예시: file:///C:/Users/.../mlflow-tutorial/mlruns
MLflow 실행
http://127.0.0.1:5000에 접속
2. Scikit-learn 모델
환경설정
environment variable 불러오기
1
2
3
4
5
6
7
8
9
| import os
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Get MLflow tracking URI from environment variable
mlflow_tracking_uri = os.getenv("MLFLOW_TRACKING_URI")
print(mlflow_tracking_uri)
|
MLflow 트래킹 URI 설정
1
2
3
4
| import mlflow
# Set MLflow tracking URI
mlflow.set_tracking_uri(mlflow_tracking_uri)
|
MLflow Experiment 설정
1
2
3
| # Create or set MLflow Experiment
experiment_name = "iris_classification"
mlflow.set_experiment(experiment_name)
|
데이터셋 불러오기
1
2
3
4
5
6
| from sklearn.datasets import load_iris
# Load dataset
iris = load_iris()
X = iris.data
y = iris.target
|
훈련, 테스트 데이터 분할
1
2
3
4
| from sklearn.model_selection import train_test_split
# Split dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
|
훈련 및 평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Start MLflow run
with mlflow.start_run(run_name="RandomForestClassifier"):
# Log tags
mlflow.set_tag("dataset", "Iris")
mlflow.set_tag("experiment_type", "Classification")
# Initialize and train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
# Log parameters and metrics
mlflow.log_param("n_estimators", 100)
mlflow.log_metric("accuracy", accuracy)
# Save model
mlflow.sklearn.log_model(model, "random_forest_model")
|
MLflow Run 이름 설정
1
| with mlflow.start_run(run_name="RandomForestClassifier"):
|
MLflow Tag 설정
1
2
3
| # Log tags
mlflow.set_tag("dataset", "Iris")
mlflow.set_tag("experiment_type", "Classification")
|
Parameter 및 Metric 기록
1
2
3
| # Log parameters and metrics
mlflow.log_param("n_estimators", 100)
mlflow.log_metric("accuracy", accuracy)
|
모델 저장
1
2
| # Save model
mlflow.sklearn.log_model(model, "random_forest_model")
|