Scikit-learn Pipeline에 PCA 포함하기
PCA(주성분 분석)
최대 분산을 보존하면서 데이터를 저차원 공간으로 변환하는 차원 축소 기법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# iris 데이터셋 불러오기
iris = load_iris()
X = iris.data
y = iris.target
# feature 표준화
X_standardized = StandardScaler().fit_transform(X)
# PCA 객체 생성
pca = PCA(n_components=2)
# 데이터에 대해 fit 및 transform
X_pca = pca.fit_transform(X_standardized)
# explained variance ratio 확인
explained_variance_ratio = pca.explained_variance_ratio_
print("Explained Variance Ratio:", explained_variance_ratio)
# 변환된 데이터 시각화
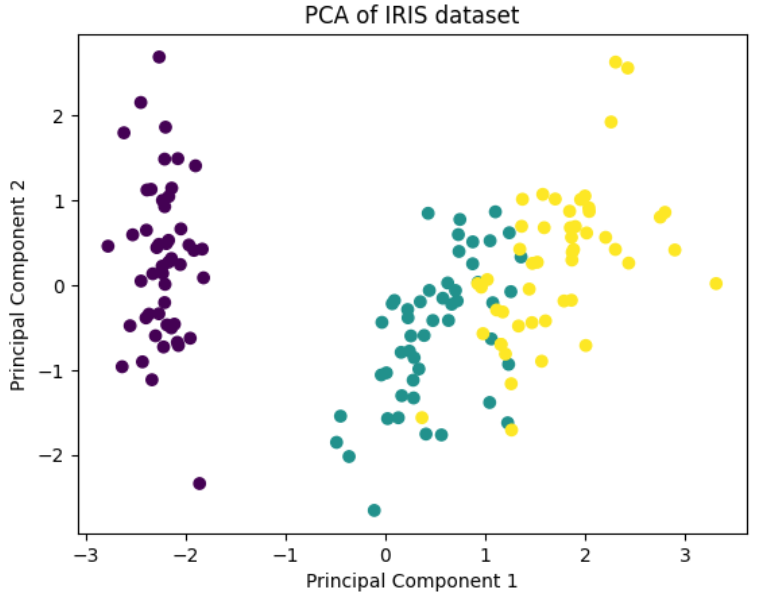
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of IRIS dataset')
plt.show()
Pipeline에 PCA 포함하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# iris 데이터셋 불러오기
iris = load_iris()
X = iris.data
# pipeline 설정
pipeline = Pipeline([
('scaler', StandardScaler()), # feature 표준화
('pca', PCA(n_components=2)) # PCA 적용
])
# 데이터에 대해 fit 및 transform
transformed_data = pipeline.fit_transform(X)
특정 feature만 PCA 적용하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
# iris 데이터셋 불러오기
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
# PCA를 수행할 feature 지정
feature_columns = ['sepal length (cm)', 'sepal width (cm)'] # 이 feature에만 PCA를 적용
# ColumnTransformer 설정
preprocessor = ColumnTransformer(
transformers=[
('scaling', StandardScaler(), slice(None)), # 모든 열에 스케일링 적용
('pca', PCA(n_components=1), feature_columns) # 선택된 feature에만 PCA 적용
# 추가 가능
])
# 최종 파이프라인 설정
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', RandomForestClassifier()) # 전처리 후 classifier 추가
])
# 데이터를 훈련 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 파이프라인을 훈련 데이터에 fit
pipeline.fit(X_train, y_train)
# 테스트 데이터에 대한 예측
y_pred = pipeline.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print("accuracy:", accuracy)
This post is licensed under CC BY 4.0 by the author.