Scikit-learn GridSearchCV에 여러 score 설정
Scikit-learn 모델을 훈련하면서 여러 score에 대해 확인하려고 한다. GridSearchCV를 설정해서 이를 쉽게 구현할 수 있다. 예시 Classification from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split, Grid...
Scikit-learn 모델을 훈련하면서 여러 score에 대해 확인하려고 한다. GridSearchCV를 설정해서 이를 쉽게 구현할 수 있다. 예시 Classification from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split, Grid...

MLflow란? 완전한 머신 러닝 라이프사이클을 관리하는 플랫폼 실험 추적, 재현 가능한 모델 개발, 모델 관리 및 배포를 통합하는 데 사용됨 팀원 간의 협업을 용이하게 하고, 모델 관리와 버전 관리를 효율적으로 처리함 빠른 모델 반복을 가능케 하여 더 빠르게 최적의 모델을 발견하고 개선할 수 있음 머...
댓글 기능 구현 작업 브랜치: https://github.com/yehoon17/recipe_management_system/tree/comment 테스트 from django.test import TestCase from django.urls import reverse from .models import Recipe, Comment, User ...
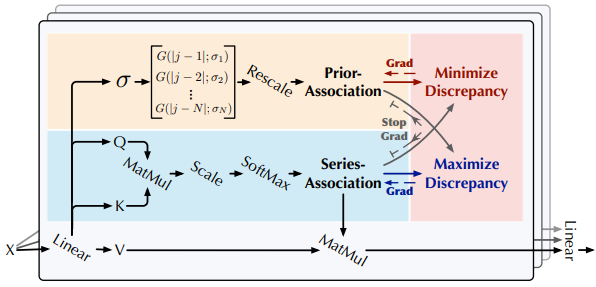
논문: Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy 코드:https://github.com/thuml/Anomaly-Transformer Anomaly Transformer의 공식 코드를 확인해봤다. 구성 main.py: config 값을 받고, So...
논문: Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy Anomaly Transformer: 트랜스포머를 활용하는 비지도 시계열 이상 감지 모델 Association Discrepancy를 도입하여 정상과 비정상 점 구별 Anomaly-Attent...
프로필 조회 및 수정, 작성한 레시피 조회 기능 구현 작업 브랜치: https://github.com/yehoon17/recipe_management_system/tree/profile 프로필 조회 및 작성한 레시피 조회 views.py @login_required def profile(request): recipes = Recipe.o...

Apache Spark란? 빅데이터 처리와 분석을 위해 설계된 오픈 소스 분산 컴퓨팅 시스템 클러스터 환경에서 대규모 데이터 세트를 처리하기 위한 통합 엔진을 제공 배치 처리부터 실시간 스트림 처리 및 기계 학습까지 다양하게 활용 Apache Spark의 주요 특징: 빠른 처리 속도...
논문: Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy 개요 시계열 이상 탐지 모델에 대해 찾아보았다. 인용수도 준수하고 Transformer를 활용한 논문이 눈에 들어와서 읽어보기로 했다. 찾아 본 영단어 Discrepancy: 차이 Adversari...
기본 회귀 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split, ...
1. Data Cleaning: 중복 제거: df.drop_duplicates(inplace=True) 결측치 처리: # 결측치를 포함한 행 제거 df.dropna(inplace=True) # 결측치 채우기(특정 값으로 채우거나 인접한 값으로 채우거나) df.fillna( value=0, # meth...